Introducing distplyr 0.2.0
When I was modelling streamflow for the Coldwater River in British Columbia, I needed to combine distributions for rainfall-driven flow and snowmelt-driven flow. In that case, one useful operation was to take the distribution of whichever component was larger.
That kind of problem is exactly why distplyr exists.
Standard named distributions like Normal, Poisson, and Gumbel are useful starting points, but they usually are not enough for real modelling work. In practice, we often need to transform distributions, combine them, or modify particular features such as point mass or hazard. Until now, doing that usually meant writing bespoke code for each case.
In fact, that need was one of the original motivations for the probaverse project, which at the time began as a single package called distplyr.
Fast forward 5 years, and distionary now handles the distribution object itself, freeing distplyr to focus on verbs for manipulating distributions.
Here is a quick look at the idea:
library(distionary)
library(distplyr)
x <- dst_norm(0, 1)
y <- dst_exp(1)
# The distribution of the larger of two draws
plot(maximise(x, y))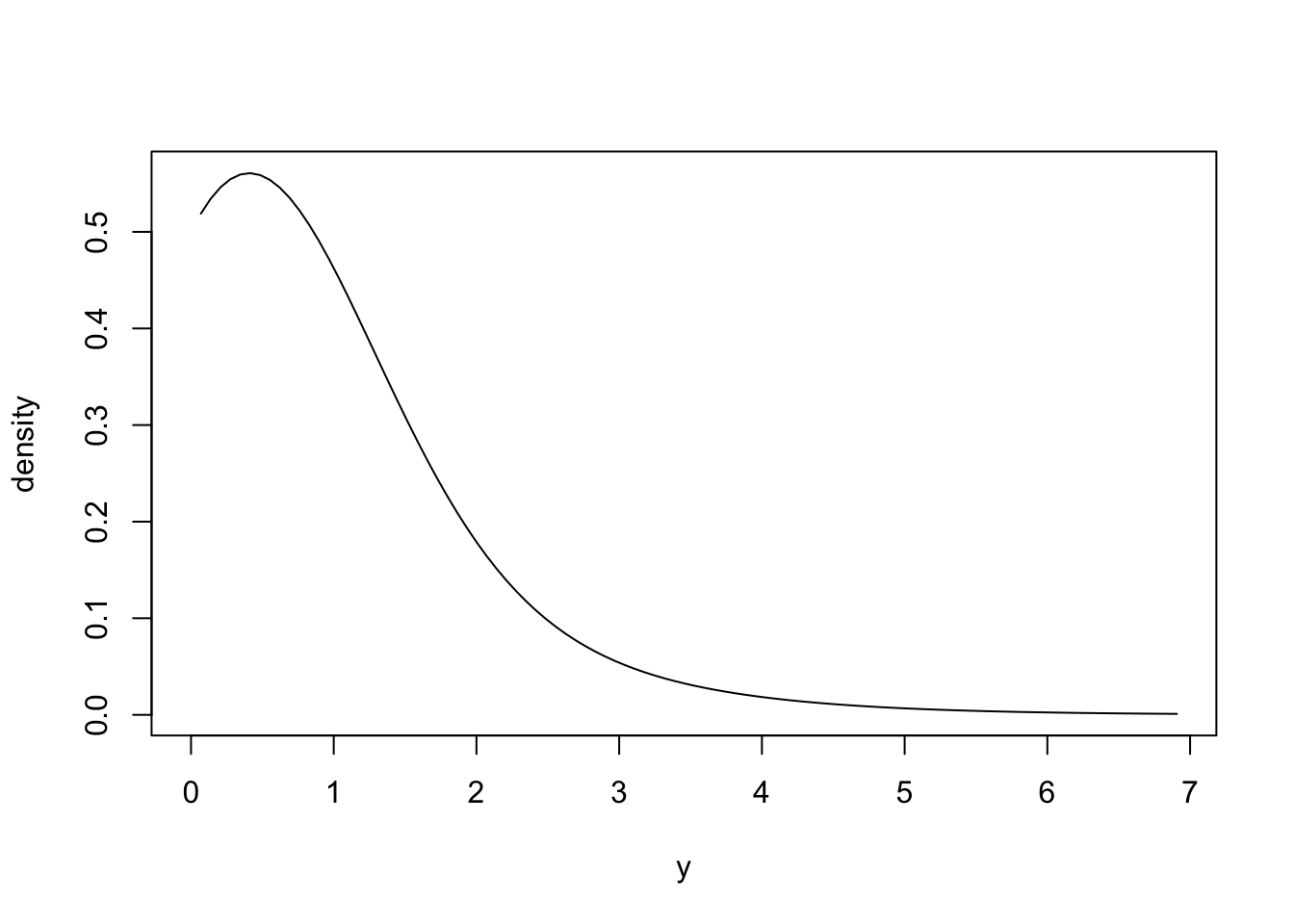
# A mixture distribution built from two components
plot(mix(x, y), n = 1000)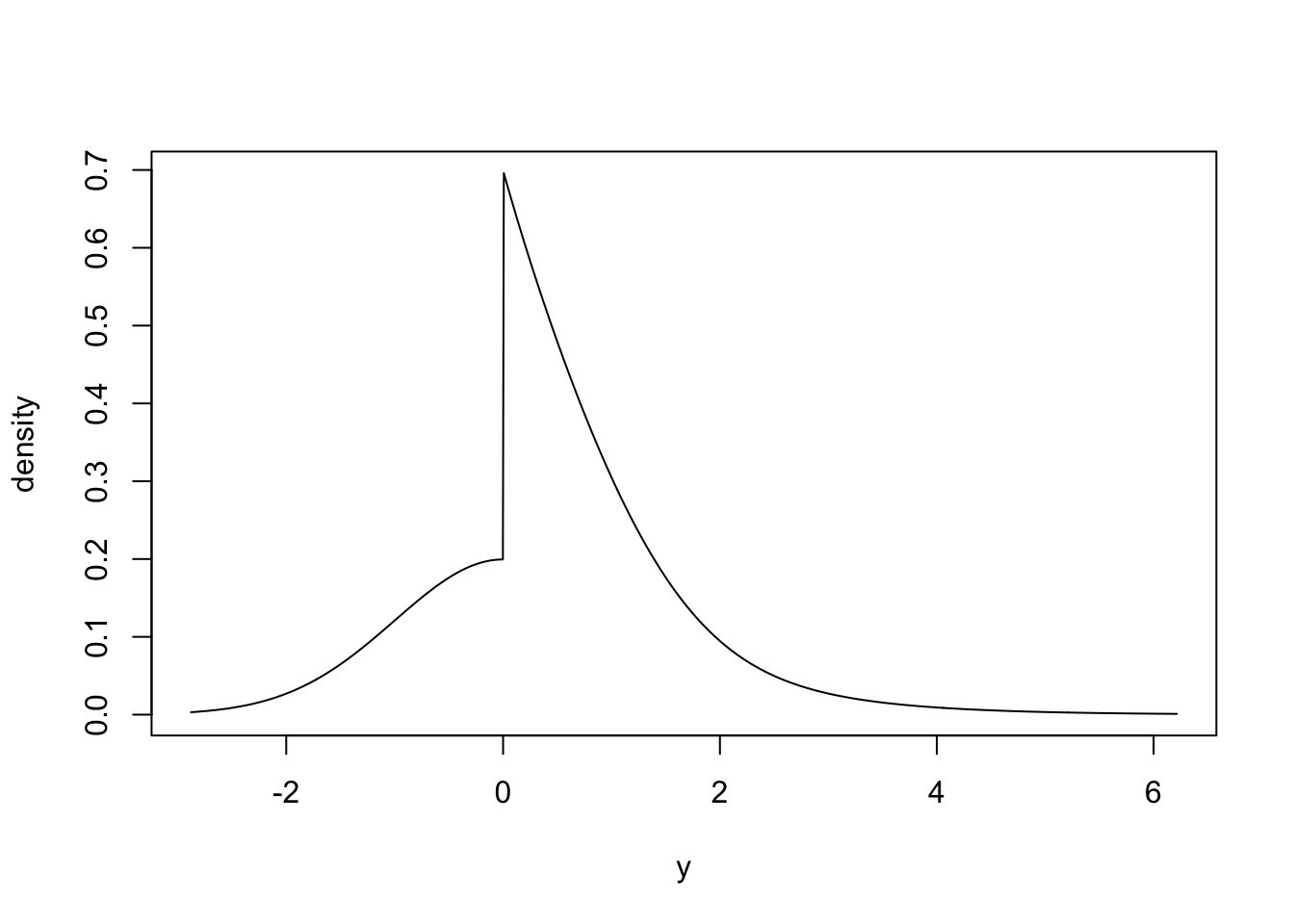
The nice part is that these are still ordinary distribution objects, so you can keep working with them as distributions:
enframe_quantile(mix(x, y), at = c(0.25, 0.5, 0.75))## # A tibble: 3 × 2
## .arg quantile
## <dbl> <dbl>
## 1 0.25 1.16e-10
## 2 0.5 4.14e- 1
## 3 0.75 1.04e+ 0mean(maximise(x, y))## [1] 1.160521This 0.2.01 release is an inaugural one for the modern distplyr: a package devoted specifically to distribution manipulation, built on top of the distribution infrastructure now provided by distionary.
There is still a lot more to add. Planned verbs include compress_mass(), graft_*() and slice_*(), inflate_hazard(), discretize(), and more. Even so, this release already makes it much easier to express modelling ideas directly in code, rather than rebuilding one-off distribution logic each time. Maybe I’m biased, but this is exactly the kind of tooling I have wanted for years, and I’m excited to keep building it out.
If you want to learn more about the broader project, take a look at the probaverse home page. The probaverse project is ambitious, and there is a lot more I would like to build, but progress on that work will depend on future funding.
distplyrversion 0.1.0 was never released to CRAN, and was based on an earlier, less consistent representation of probability distributions.↩︎